Scene Aware Vision Language Action Modeling for Robotic Manipulation
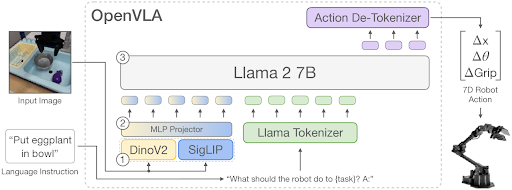
In the rapidly evolving field of human-robot interaction, the challenge of developing robots that can perform actions based on human instructions has been a key research goal. This project investigates Scene Aware OpenVLA, a modified version of the Vision Language Action Model (VLA) designed to improve robotic manipulation tasks using 7-DOF (degrees of freedom) robotic arms.
Project Highlights:
- Input: RGB images of the workspace and natural language task instructions.
- Output: Discrete N-DOF joint parameters for robotic task execution.
- Challenges: Addressed issues like limited real-world understanding, catastrophic forgetting, and the need for re-training when adding new tasks.
- Methodology: We enhance OpenVLA by incorporating attention masks to extract object-specific visual features, integrating Chain-of-Thought (CoT) Reasoning using GPT-4 for task instructions, and using PointNet for depth information, improving task understanding and execution.
Results:
Our Scene Aware OpenVLA achieved a significant improvement in success rates:
- OpenVLA: 58% ± 3.1%
- Scene Aware OpenVLA (CoT only): 60% ± 1.9%
- Scene Aware OpenVLA (CoT + BBox): 61% ± 1.4%
- Scene Aware OpenVLA (CoT + Depth): 66% ± 2.2%
Future Work:
- Closed-loop control for next-state prediction to enhance model robustness.
- Extending the method to real-world robotic manipulation experiments.
- Exploring further improvements in object detection and commonsense reasoning in VLAs.
If you have suggestions or would like to collaborate, feel free to reach out!
Best,
Aryan Shetty